Introducing raphGPT v2
24 June 2025
Today, I’m launching something that’s taken me almost 2 years to build now, and today marks the biggest release of this telegram bot that I’ve always envisioned.
raphGPT has always been something I wanted to build, ever since gpt-2-simplegpt-2-simple and DialoGPTDialoGPT made its rounds in the open source developer community in June 2019. I still remember jogging at the park when I saw the first release, and rushed home to try it out. I was so excited.
I will be documenting everything that went into this bot, starting from how it works below.
The bot is built on a multi-modal LLM architecture. It accepts text, voice, video, images, documents (pdf, docx) and files.
From the beginning
I had something going in 2020: https://github.com/raphtlw/transformershttps://github.com/raphtlw/transformers
It was a web frontend to a GPT-2 transformer model running on Google Cloud Run.

It doesn’t work anymore, but it used to be able to just generate text, based on your prompt.
Fast-forward to launching raphGPT on Cloud Run, and hosting turned into a puzzle: with only 2 GB of RAM available, I had to experiment relentlessly to find the sweet spot for model parameters, trim down the context size, and settle on <|end_of_text|> as the stop token to keep responses clean and prevent overruns.
Fortunately these days, we have things like OpenAI, Hugging Face, and LangChain that let me plug into world-class LLMs in minutes instead of wrestling with 60 GB weights or GPU queues. With OpenAI’s API handling inference, I can forget about RAM limits and focus on fun stuff: building memory graphs, and improving models using the fine-tuning APIfine-tuning API.
What’s so interesting
The biggest technical achievement from this project is how it processes video messages.
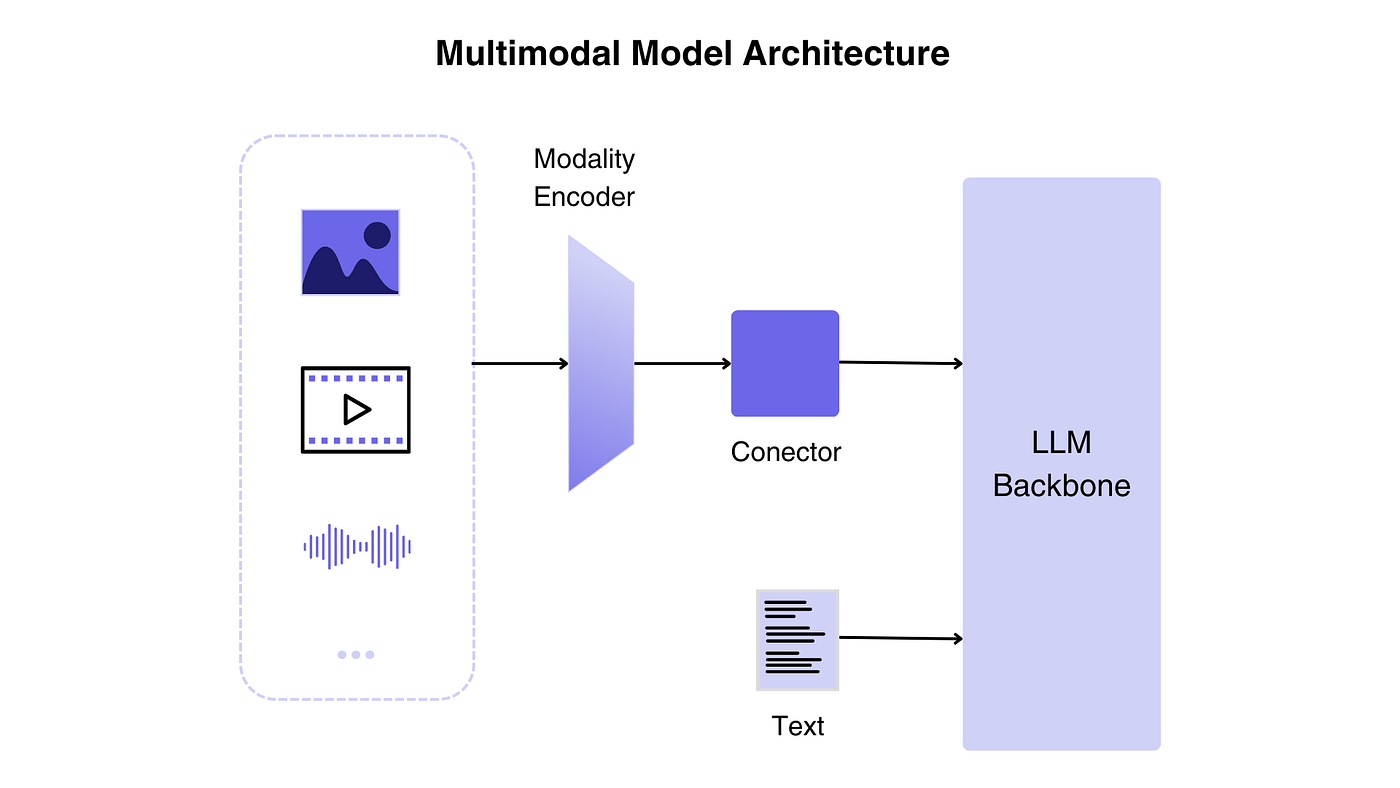
LLMs can only take in a series of images as input.
Think about it… what are videos made up of?
- Audio
- Still frames, but they just happen to change quickly
Audio can be easily processed. Any of the 3 ways: tonal analysis, transcription, emotional analysis.
The more interesting part is how video is processed.
It works similar to how a smartphone camera works, with the concept of “zero-shutter-lag” (ZSL) and anti-blur features.
As @sdw, the creator of halide camera puts it@sdw, the creator of halide camera puts it, Zero Shutter Lag lets you take photos—before they are taken.

Relying on 2 big ideas:
- Continuous capture into a rolling buffer
- Smart frame-selection (and/or multi-frame fusion)
As soon as you open the camera app, the image sensor is already capturing frames into a buffer in a fast on-chip memory. When the shutter button is pressed, you tell the chip to save the buffer. The ISP freezes the ring buffer, copies it to the CPU for processing, and continues running the buffer.
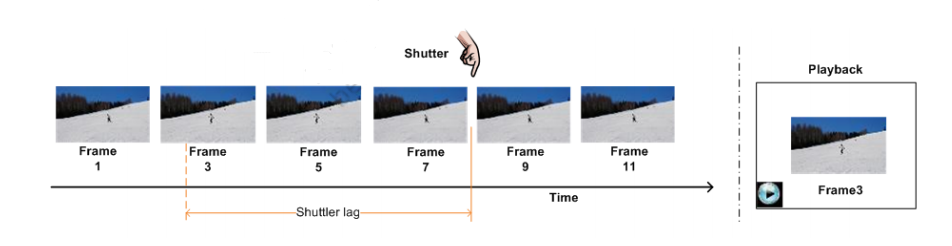
Taken from 图像处理 • 实时互动网图像处理 • 实时互动网
Some code is run to extract the clearest frames in the buffer. This is done using an algorithm known as laplacian variance, which is a pre-defined 3x3 matrix that’s used to calculate the degree of rapid intensity change in an image (scanning through the entire image). This allows the camera to filter out the images with the sharpest edges and least amount of blur.

Taken from cvexplained.wordpress.comcvexplained.wordpress.com
To understand how it works, it involves logic and matrix multiplication but essentially just think of it as a row of numbers that have some kind of algorithm run through each row, and then the average of the result is calculated. I won’t go further into detail but you can just look up scholarly articles or explanations available on the vast web out there.
A blur metric is computed on each frame, and compiled. At the end of the frame buffer, only the frames with the least amount of blur are included in the final calculation. The frame with the highest “sharpness” score—and usually best exposure/histogram gets promoted as “the” shot. On some phones, it’s literally “pick one” and on others they may include the best frames for features like “top shot” or “live photo” (found on Pixels and iPhones)

Taken from High Dynamic Range (HDR) Technology for MobileHigh Dynamic Range (HDR) Technology for Mobile
The resulting frames are then stabilized and fused together, to create the best image possible. This is known as HDR on some devices. The more images the device is able to align together in the same frame, the higher the dynamic range of the shot. The ISP’s multi-frame noise-reduction and de-motion-blur engine aligns and merges them into one final image. This is also how your phone sometimes “sees” more than you can in the dark, or when some phones have “night mode” which allows photos to be clearer and more detailed at night.
Full “still-photo” pipeline on the chosen/merged frame(s) all happen on the ISP.
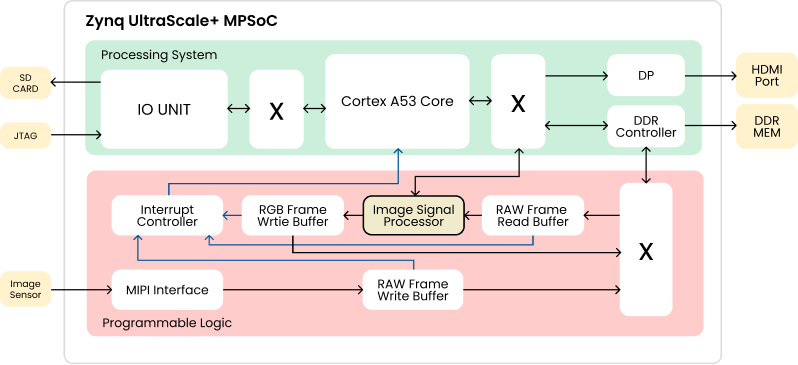
Demosaic raw Bayer data → white balance → lens-shading correction → tone-mapping → sharpening → JPEG/HEIC encode.
This all happens in the ISP (Image Signal Processor) or on a dedicated NPUs/ISP pipelines for sub-100 ms turnaround.

Taken from Open Image Signal Processor (openISP)Open Image Signal Processor (openISP)
The bot works in a similar way.
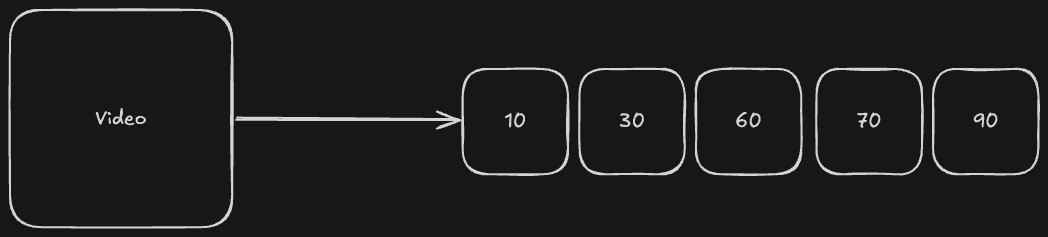
Located inside the video-parser directory, it analyzes uploaded video (or, by analogy, multiple photo frames), finding the best frames, and summarizing contents.
It mimics the phone camera’s “find the best moment” system, but does it for multiple frames, not just one. It takes a tele-bubble and extracts only the most significant frames with moments that the LLM will need to “see”.
- Instead of a live camera buffer, a sample frame is generated from the video every
stepframes (e.g., every 10th frame). - Effectively, it builds a buffer of frames from which it can search for the best.
Then, for each sampled frame:
- Uses Laplacian variance (classic sharpness detector) to calculate a blur score.
- Looks for over/under-exposed areas to calculate an exposure metric.
- Uses Mediapipe to count faces (e.g., prioritize human subjects).
- Scores all sampled frames; sorts and keeps the top 5 by the score above.
Face detection has higher priority because humans possess a remarkable ability for face recognition, and I wanted to achieve a similar effect in the bot.
See it in action:
After processing:

Of course the answer was: 2
Why did I make this?
First, for myself to use. I gotta be honest, this whole thing was started because I wanted to build something that could do things for me, allow me to get up to write code, so you could send a ZIP file of your project, ask for some changes and get it back in a zipped file. This is possible now with the codex_agent tool.
I’ve always been fascinated with LLMs and how they worked. At the end of the day, they’re just autocomplete machines. If we can get them to do useful and beneficial things for the good of humanity, I consider the pursuit of this whole industry a success.
More importantly, the foundations are complete. This means I can now experiment with tools built into the bot that people might find useful. Things like getting directions, setting reminders, and being able to simply just forward a message, or send a photo to ask for information about something that they are talking about with their friends. I have seen it help my thought processes and decision making in a way that could not have been possible without it. That’s why I’ll continue to keep this project alive, and it will always be something that I can work on if I want to.
V1
V1 turned out to be worse than I ever thought. Not because of how it worked, but how the project was executed. A quick look at the file structure tells you plenty:
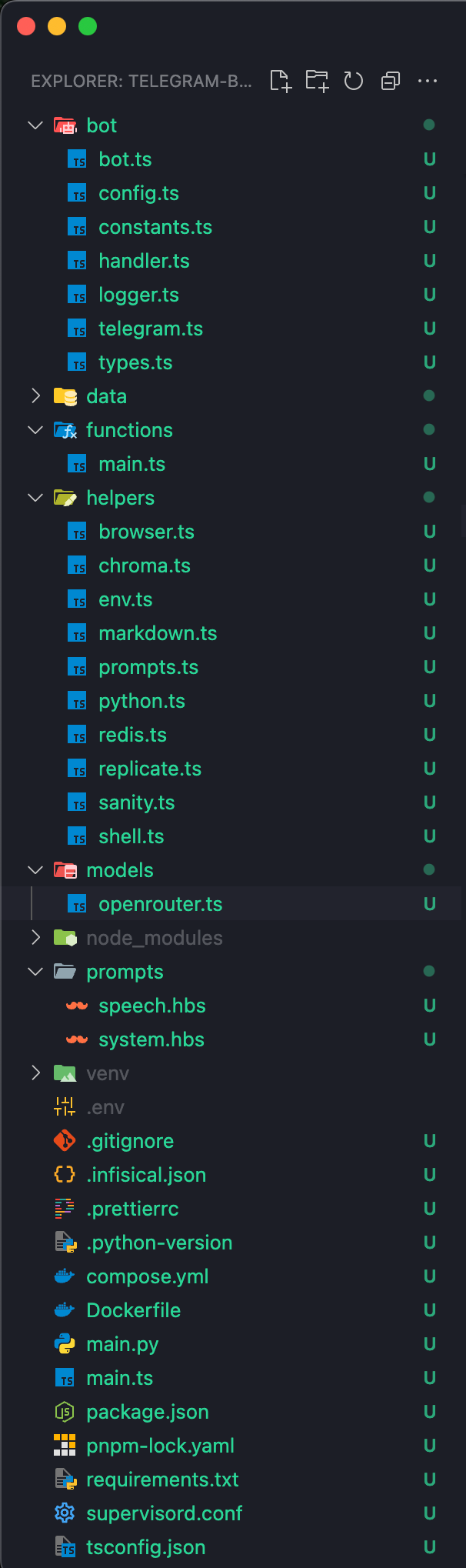
It used supervisord as the init system in Docker, and both the Python and Node.js code was together in the same directory, and the two runtimes were bundled together in the same docker container.
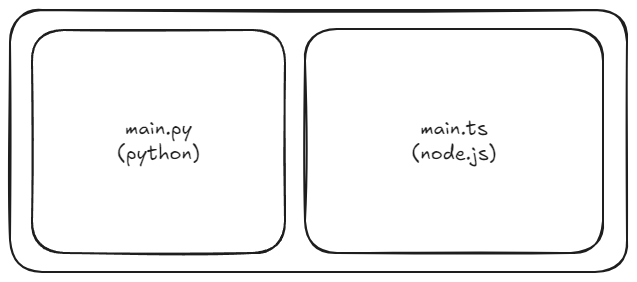
This meant the two had to share one container, and that container was ever only used for production, not development.
I remember at one point, as I was trying InfisicalInfisical, I installed Infisical inside the container and tried to generate the .env file using the machine ID credentials. There were so many bad practices that were in place in the first version, and I wasn’t proud to release it. I’m so thankful for the opportunity to document these down here, so I can learn from these mistakes.
Running this whole setup was a matter of starting 3 terminals. One with the docker compose command launching redis, gotenberg and chromadb, the other with python running main.py, and lastly the pnpm command running main.ts.
This was the Dockerfile from V1
# syntax=docker/dockerfile:1
FROM debian:latest AS base
RUN apt-get update \
&& apt-get install -y locales gnupg wget curl ca-certificates coreutils \
# Install Infisical
&& curl -1sLf ‘https://dl.cloudsmith.io/public/infisical/infisical-cli/setup.deb.sh’ | bash \
&& apt-get update \
&& apt-get install -y infisical \
# Note: this installs the necessary libs to make the bundled version of Chrome that Puppeteer
# installs, work.
&& wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | gpg —dearmor -o /usr/share/keyrings/googlechrome-linux-keyring.gpg \
&& sh -c ‘echo “deb [arch=amd64 signed-by=/usr/share/keyrings/googlechrome-linux-keyring.gpg] https://dl-ssl.google.com/linux/chrome/deb/ stable main” >> /etc/apt/sources.list.d/google.list’ \
&& apt-get update \
&& apt-get install -y google-chrome-stable fonts-ipafont-gothic fonts-wqy-zenhei fonts-thai-tlwg fonts-khmeros fonts-kacst fonts-freefont-ttf libxss1 dbus dbus-x11 \
—no-install-recommends \
&& apt-get update \
&& apt-get install -y make git zlib1g-dev libssl-dev gperf cmake clang libc++-dev libc++abi-dev \
—no-install-recommends \
# Install runtime dependencies
&& apt-get install -y zip unzip ghostscript graphicsmagick ffmpeg \
# Install process manager
&& apt-get install -y supervisor \
&& rm -rf /var/lib/apt/lists/*
RUN localedef -i en_US -c -f UTF-8 -A /usr/share/locale/locale.alias en_US.UTF-8
ENV LANG=en_US.UTF-8
RUN rm -f /etc/machine-id \
&& dbus-uuidgen —ensure=/etc/machine-id
COPY . /app
WORKDIR /app
# Generate .env file
RUN —mount=type=secret,id=infisical-token,env=INFISICAL_TOKEN \
infisical export \
—projectId 6fd5cbbf-ddf0-47b5-938b-ff752c3c6889 \
—env prod \
> .env
# Install Python + dependencies
RUN git clone —depth=1 https://github.com/pyenv/pyenv.git “$HOME/.pyenv”
ENV PYENV_ROOT=“/root/.pyenv”
ENV PATH=“$PYENV_ROOT/bin:$PATH”
ENV PATH=“$PYENV_ROOT/shims:$PYENV_ROOT/bin:$PATH”
RUN pyenv install $(cat .python-version)
RUN —mount=type=cache,id=pip,target=/root/.cache/pip pip install -r requirements.txt
# Install Volta
RUN curl https://get.volta.sh | bash
ENV VOLTA_HOME=“/root/.volta”
ENV PATH=“$VOLTA_HOME/bin:$PATH”
# Install Node.js and PNPM
RUN volta install node@latest
RUN volta install pnpm@latest
ENV PNPM_HOME=“/root/.local/share/pnpm”
RUN —mount=type=cache,id=pnpm,target=/root/.local/share/pnpm pnpm install —frozen-lockfile
# Setup process manager
RUN mkdir -p /var/log/supervisor
COPY supervisord.conf /etc/supervisor/conf.d/supervisor.conf
CMD [ “/usr/bin/supervisord” ]Additional information about V1
raphGPT V1 was a Telegram bot that provides:
- Conversational LLM (Large Language Model) chat capabilities (primarily using OpenAI GPT-4o and related LLMs)
- Multimedia message processing (voice, video, images, PDFs, stickers, documents, locations)
- Memory (short- and long-term) over conversations (“context window”)
- Tool use: internet search, weather, text-to-speech, image generation, Anki deck creation, file reading, payment handling, and more
- Payment and credit system with Stripe and Solana blockchain wallet integrations
- Logging, observability, and admin personality management
- Extensible via a toolbox for domain-specific actions (e.g., interacting with Solana, generating Anki decks, etc.)
Containers and Services
- bot: The main TypeScript/Node.js-based Telegram bot service (plus supporting scripts).
- redis: Used for fast cache, pub/sub, and storing ephemeral conversational state and message history.
- chromadb: Persistent, fast vector database for semantic search and recall of past chat history (for context/LLM memory).
- gotenberg: A document conversion service, used to convert files (e.g., DOCX to PDF/Image).
TypeScript/Node.js: Main bot logic, orchestration, database integration, and the majority of features. Python (FastAPI) (main.py, openai/training.py, openai/validation.py): For advanced video/audio/image processing, custom ML scripts, data ingestion and validation for fine-tuning.
End-to-End Workflow
All services (bot, redis, chromadb, gotenberg) start via Docker Compose. Node and Python dependencies (see package.json and requirements.txt) are installed via the Dockerfile.
main.ts (TypeScript) — launches the Telegram bot, sets up logging, browser automation (via Puppeteer+Chrome), DB connections, and registers all handlers. main.py (Python + FastAPI) - launches an HTTP API for lower-level video/audio frame extraction and processing via OpenCV, Numpy, ffmpeg, etc.
Receiving Messages
- Users interact via text, voice, images, documents, stickers, video messages, etc.
- The bot (using the grammy library) processes incoming messages in bot/handler.ts.
- Authentication/registration for new users is handled, with management of credits/free-tiers.
Each message is stored short-term in Redis and long-term in ChromaDB as embeddings, enabling context-aware responses and retrieval-augmented generation. Recent tokens/messages are assembled into the LLM prompt, along with past highly-relevant memories fetched from ChromaDB.
The bot constructs an input prompt for the current message using a Handlebars template (prompts/system.hbs) filled with current time, language, personality, memory snippets, etc, and assembles a list of CoreMessage objects for processing.
The LLM (OpenAI GPT-4o or others) is invoked via ai-sdk, possibly calling “tools” (functions) if needed.
”Tools” (see functions/) can perform actions such as running web searches, reading files, generating images, producing TTS output, interacting with Google Maps, etc. Tools are dynamically selected using semantic similarity via chroma tool collection based on the LLM’s needs.
Multimodal Processing
- Images, videos, audio, stickers, etc., are downloaded, stored in a temp directory, processed
- For videos: Specific frame selection and deblurring in FastAPI/Python (using FFT, OpenCV, numpy) — see main.py.
- Audio: Transcription via Replicate/Whisper or OpenAI APIs.
- Images: Direct use, or conversion to text/Markdown via OCR or browser automation.
- Documents (PDF, DOCX, ZIP): Processed via gotenberg, pdf2pic, or unzipped to disk and chunked/read as needed.
Persisting, Following Up, and Streaming
- Each conversational turn is stored/memoized, both short- and long-term.
- Streaming LLM responses (text & audio) are handled for large messages.
- Final output is parsed, split, and sent to the user via Telegram message, possibly with voice or images.
- Usage is metered for free tier/paid users. Payment and credit can be bought via Stripe or by topping-up via Solana wallet (wallet integration, payments, and notifications managed).
Special Features
- Personality is editable by an admin directly in Telegram (with custom inline keyboard navigation).
- Users can buy tokens via Stripe or using Solana; bot manages wallet balances/notifications.
- Toolbox tools auto-populate based on similarity with the query; new tools can be added easily.
Observability
Logging goes to Grafana Loki (plus pretty print in development). Detailed logs are generated for tracing message flow.
Fine Tuning of Custom Model
Python scripts in openai/ (training.py, validation.py) prepare custom conversational data from Telegram chat export JSON, process it into OpenAI fine-tuning format, and check for data quality/errors before submitting to OpenAI for model fine-tuning.
Database and Redis
db/schema.ts defines schema in SQLite (with Drizzle ORM):
- users: Telegram-user info, credits, wallet info, message count, etc.
- personality: Personality texts for persona injection.
- solana_wallets: Solana wallet info for each user.
- local_files: For storing uploaded file data.
- ChromaDB stores high-dimensional embeddings for text snippets; enables retrieval-augmented conversations and dynamic memory.
- Redis tracks ephemeral chat state, conversation turns, and rate limits.
ChromaDB stores high-dimensional embeddings for text snippets; enables retrieval-augmented conversations and dynamic memory. Redis tracks ephemeral chat state, conversation turns, and rate limits.
Development
-
Fully containerized: Everything is made for docker compose up.
-
Cross-service orchestration: Node talks to FastAPI Python via HTTP.
-
Easy to add functionality: Add new tools to the toolbox in functions/toolbox.ts.
-
CI/CD: GitHub Actions workflow builds and pushes Docker images to GHCR.
-
Dependencies: Docker, Python 3.12+, Node 20+, pnpm
-
Start all containers/services:
docker compose up redis gotenberg chromadb -
Start Python FastAPI service:
uv venv source .venv/bin/activate.fish fastapi dev main.py —port 26691 -
Start TypeScript/Node service:
pnpm dev
Ideology of development
- Modular, extensible, designed so new capabilities (“tools”) can be added at will and are discoverable automatically by the LLM or by admin action.
- Personality, credits, payments, and state are per-user and persisted.
- A rich set of dev, formatting, and linting tools (prettier, ESLint, TypeScript strict mode) are used to enforce code quality.
Meant to be a state-of-the-art Telegram AI assistant with deep memory, multimodal (text, voice, video, documents, images) understanding, support for both fiat and crypto credits, web/real-world tool integrations, and smart conversational capabilities, all built for easy extensibility and production deployment.
It was time for a revamp
There came a point when the bot wasn’t working correctly. I was still hosting it on my home server at home, and I left it unattended for 3 months. As I moved things around in my house, I also set new systems up, and a new build to use as a home server. This is when things started to break with the bot and the 5 docker containers that were running separately from each other, and I figured it was time to start working on a better, more reliable version that could be hosted on the cloud.
It was a matter of “this architecture and file structure” just wouldn’t cut it any further, and it was past its experimentation stages. This brought me back to the reason why I made this bot: so more people can have access to a useful and guided AI agent. So I can also use the tools that are built in to perform tasks that would otherwise require downloading other apps or working on a computer.
So that’s what I did with V2.
V2
This was the real deal. It was the production copy. Everything I wanted to include in a swiss-army knife toolbox for my ideal LLM that would be able to help me throughout the day was built in this implementation from the ground up.
Everything is now within Docker, and the Dockerfiles are written in a way that allows them to be cache-dependent, which means developing is easier now. Just saving the file causes docker to sync the files from the local machine into the running container. Puppeteer from the previous setup is now a browserless Docker container defined in compose, and so the container need not be so “fat”.
So what can it do?
-
Telegram bots are notorious for privacy concerns. I wanted to put privacy first, so I implemented a /clear command, which wipes the database completely of your messages and I will never be able to see it.
-
Media groups —you can send groups of photos and the bot would take it as one big message.
-
Interruptions. You can keep sending more and more messages, and as long as the bot didn’t finish what it was about to say, it will start over, taking the newer messages into account.
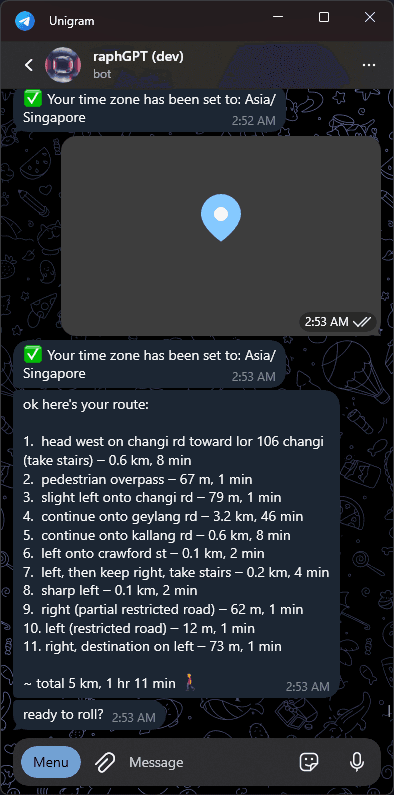
-
Places and Navigation tools allow you to quickly find a place, find restaurants near you, look up the location of the most popular place in town, and even get directions to that place, right from within the bot.
-
Message scheduling. You can now schedule messages for sending later.
-
LTA DataMall API. It now has connectivity to LTA’s data APIs which (if you live in Singapore), you can benefit from the vast availability of transportation devices and methods. The bot can now tell you:
- Which bus stops are available near your location
- How to get to a bus stop
- What time the bus will arrive
- What time the next 3 buses will arrive
- What is the passenger volume of the bus
- What is the passenger volume of the train
- When the first train will be arriving (at your location)
- When the last train will be arriving (at your location)
- What stops a specific bus number goes through
- What bus numbers are available for a specific stop
-
Failure and error handling. If a message fails to process for any technical reasons due to connectivity, the bot keeps the message in redis and refers back to it when you send another message, telling it to retry.
-
Solana blockchain integration. You can look up any wallet by address or .sol Bonafide address and have it tell you things like:
- Last 10 transactions, and value
- Top 15 transactions, and value
- How recent their last transaction was
- Current wallet value in SOL or USDC
-
agentic.soagentic.so integration, which consists various LLM tools that are useful for general questions
-
Codex CLI integration. It’s also able to operate on a zip file you send in to the bot, work on your project per your instructions, and send it back. It’s really cool and I’d love for you to try it out.
Now, to get up and running with development, all I need to do is to open up a terminal and run:
docker compose watchHere are the most significant improvements this release has over the previous few ones:
Messages, no matter what modality, they get summarized and the chat is turned into a single query that’s used to perform semantic search on the chat history, and only the top 4 most relevant conversation turns are included.
Tools also undergo the same process. The query is used to search through the tool database to see which ones score the highest in terms of semantic similarity, and the 10 highest scoring tools are included in the LLM call (using Vercel’s AI SDK).
Telegram tools are separate, however. This means all telegram related tools to connect the LLM directly with Telegram’s API are included in always by default. They allow agents to perform things like send messages (not only to the current user, but to other users), cancel response generation, send files, send photos, send videos, and forward messages. The bot can even send polls now, a feature meant for group chats.
Messages now output in batches denoted by <|message|>, which allows the bot to send multiple messages at one go, compared to what was previously possible, which was to send the entire long and windy chunk, difficult for users to read.
let textBuffer = "";
let firstMessageSent = false;
const flushBuffer = async () => {
console.log(`About to flush: ${textBuffer}`);
// flush the buffer
if (textBuffer.trim().length > 0) {
const mdv2 = telegramifyMarkdown(textBuffer, “escape”);
await telegram.sendMessage(ctx.chatId, mdv2, {
parse_mode: “MarkdownV2”,
…(ctx.editedMessage &&
!firstMessageSent && {
reply_parameters: {
message_id: ctx.msgId,
},
}),
});
textBuffer = "";
firstMessageSent = true;
}
};
for await (const textPart of textStream) {
textBuffer += textPart;
if (
textBuffer.trim().endsWith(”<|message|>”) ||
textBuffer.trim().endsWith(”</|message|>”)
) {
textBuffer = textBuffer.replaceAll(”<|message|>”, "");
textBuffer = textBuffer.replaceAll(”</|message|>”, "");
await flushBuffer();
}
}
await flushBuffer();This is a buffer mechanism to allow flushing of messages generated from a stream. The model is instructed to output a series of messages in that format.
Did I also mention agents that call other agents? They are entities that keep track of their own context memory, can call other agents, and answers back to the main agent.
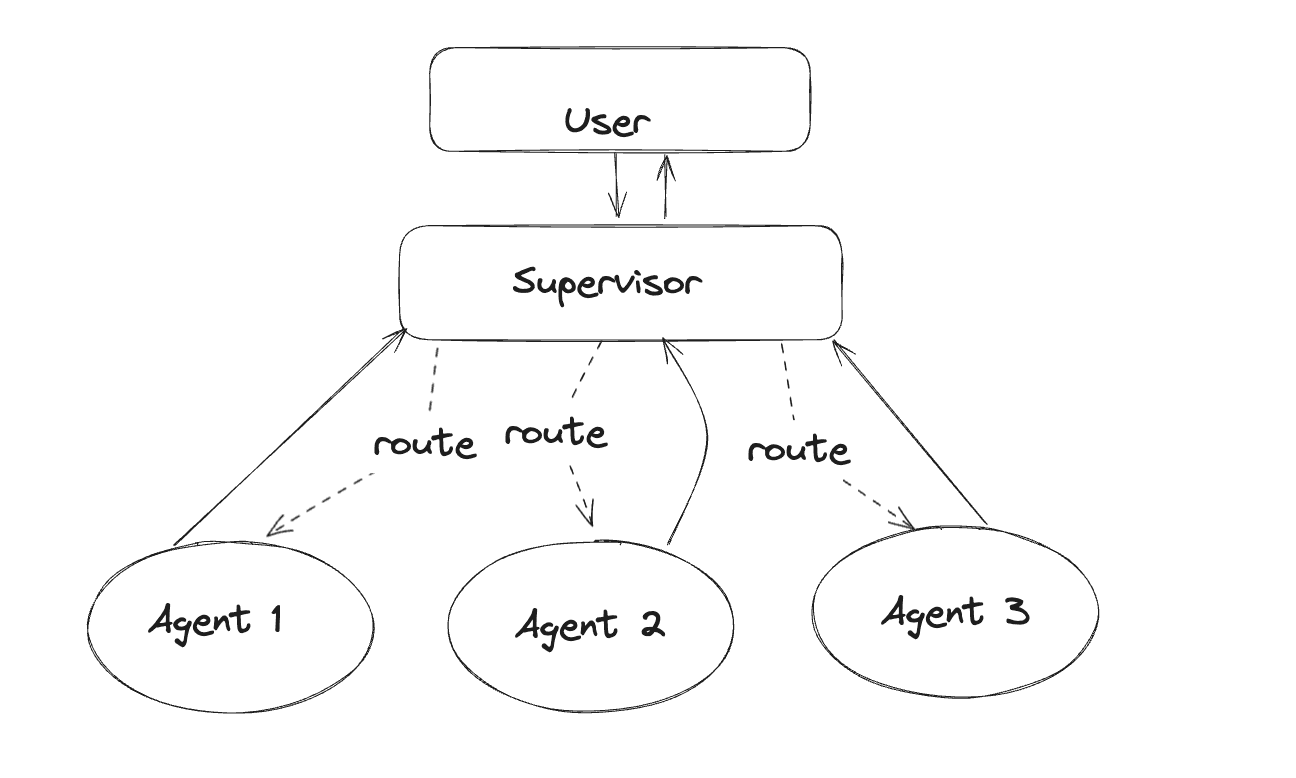
It’s a very cool concept, because not only do these AI models have the ability to call tools, they can also run other agents. For example, wouldn’t it be nice if an excel file modification agent could run say, the schedule_message tool? This would allow the model to schedule messages to other “contacts” based on the contents of the excel spreadsheet. For instance, you want it to go over the guest list for a birthday party and send each one of them a custom email.
There is now a task queue, which allows the bot to run longer tasks that require more time to complete. For now, there is only one task defined, the codex CLI. Once a run is complete, and the CLI has finished working with your project, it zips the entire project and sends it back to you.
Other changes include:
- Message attachments stored in S3, all files are handled as S3 keys
- Files are browsable and viewable any-time (by the bot) by S3 key
- Dedicated image generation agent
- LTA DataMall API connectivity + agent
- Google Maps Directions API
- Google Maps Places API
- Crontab for improved scheduling
- Middleware which creates a tempDir for the session, and deletes it after the run is complete
I just want to thank you if you read this post this far. Building this was a huge technical feat for me and it allowed me to learn all the ins and outs of LLMs.
Today, I will be open-sourcing the repo, so anyone is able to download the source code, suggest improvements and even build their own custom LLM-powered Telegram bot.